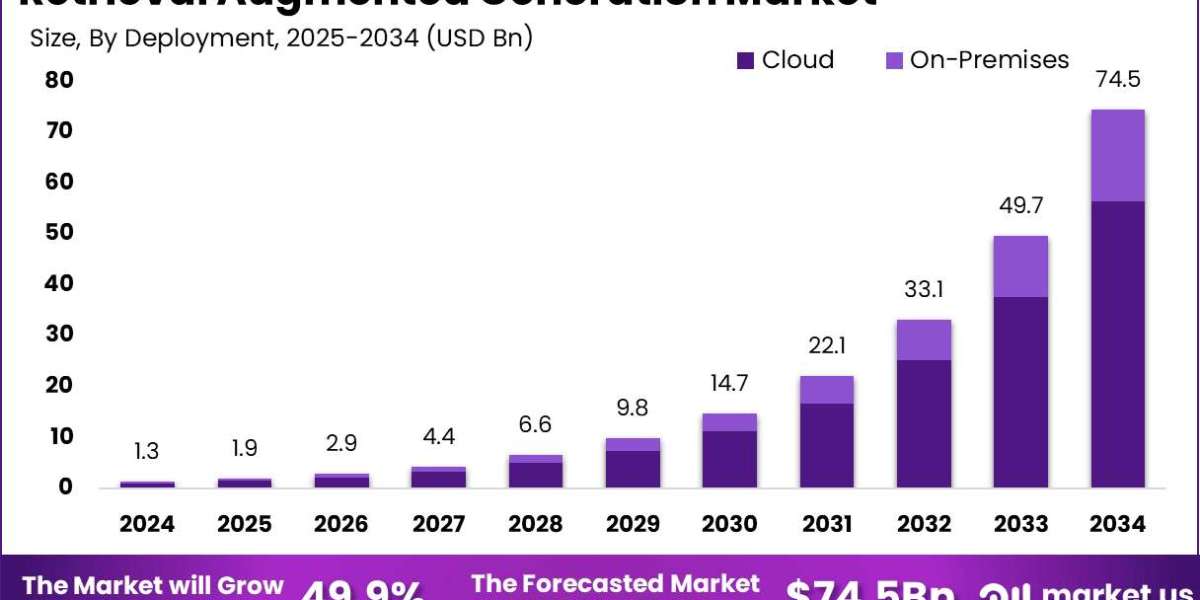
Retrieval augmented generation is an approach that blends large language models with targeted external knowledge sources so that responses are grounded, up to date, and verifiable. In plain terms, it lets a generative model fetch the most relevant documents or data pieces and use them to produce answers that feel both fluent and factual. This market spans vendors offering retrievers, vector stores, connectors to enterprise content, and turnkey pipelines that stitch retrieval and generation together. Buyers value reduced hallucination, faster access to domain knowledge, and the ability to customize outputs to company-specific information. Providers compete on retrieval accuracy, latency, integration simplicity, and how well their systems preserve provenance and audit trails.
Read more - https://market.us/report/retrieval-augmented-generation-market/
The broader market environment for retrieval augmented generation covers solution providers, cloud platforms, system integrators, and open source projects pushing the technology into production. Demand comes from industries that need safe, explainable AI over private data such as professional services, healthcare, finance, and customer support. The market’s growth is shaped by ease of deployment, the maturity of vector databases, and vendor partnerships with major cloud providers. Customers evaluate total cost of ownership, data governance features, and the ecosystem of prebuilt connectors when choosing a supplier. Competitive advantage accrues to companies that balance high retrieval quality with clear controls for privacy and compliance.
Fundamental drivers behind interest in retrieval augmented generation include the practical need for trustworthy outputs, the rising volume of unstructured enterprise data, and the desire to deliver personalized user experiences. Organizations are moving away from generic, closed-box generation toward systems that can cite sources and let subject matter experts validate content. Improvements in embedding techniques and search algorithms also make retrieval more precise, which in turn raises confidence for business use. Another subtle driver is developer productivity: teams can build domain-aware assistants faster by combining retrieval components with generative layers rather than training huge custom models from scratch.
Demand analysis shows that use cases with high value on accuracy and traceability are the most compelling buyers for retrieval augmented generation. Customer support that must reference manuals, legal teams needing citeable drafts, and research workflows that require rapid literature scans all find clear ROI. Adoption is accelerating thanks to a stack of enabling technologies such as performant vector stores, scalable embedding services, and secure connectors to enterprise content repositories. Organizations often pilot the technology in a single department and then expand as governance patterns and performance targets are proven, which helps de-risk broader rollouts.
Companies choose retrieval augmented generation for a few practical reasons that make it attractive over alternative approaches. The ability to ground answers in controlled documents reduces the risk of costly mistakes and reputational harm, which matters deeply in regulated industries. It also enables richer, context-aware interactions without demanding massive compute to fine tune or retrain base models. Teams appreciate the modularity: they can swap retrievers, update knowledge bases, or tighten security controls independently of the generative model. This modularity lowers long term maintenance friction and aligns better with existing data architectures.
Investment opportunities lie across several layers of the stack, from specialized vector databases and retrieval APIs to integrators that build verticalized solutions for sectors with acute compliance needs. There is also room for tools that simplify













